via vim-galore

A plugin may grow and become quite long. The startup delay may become noticeable, while you hardly ever use the plugin. Then it's time for a quickload plugin.
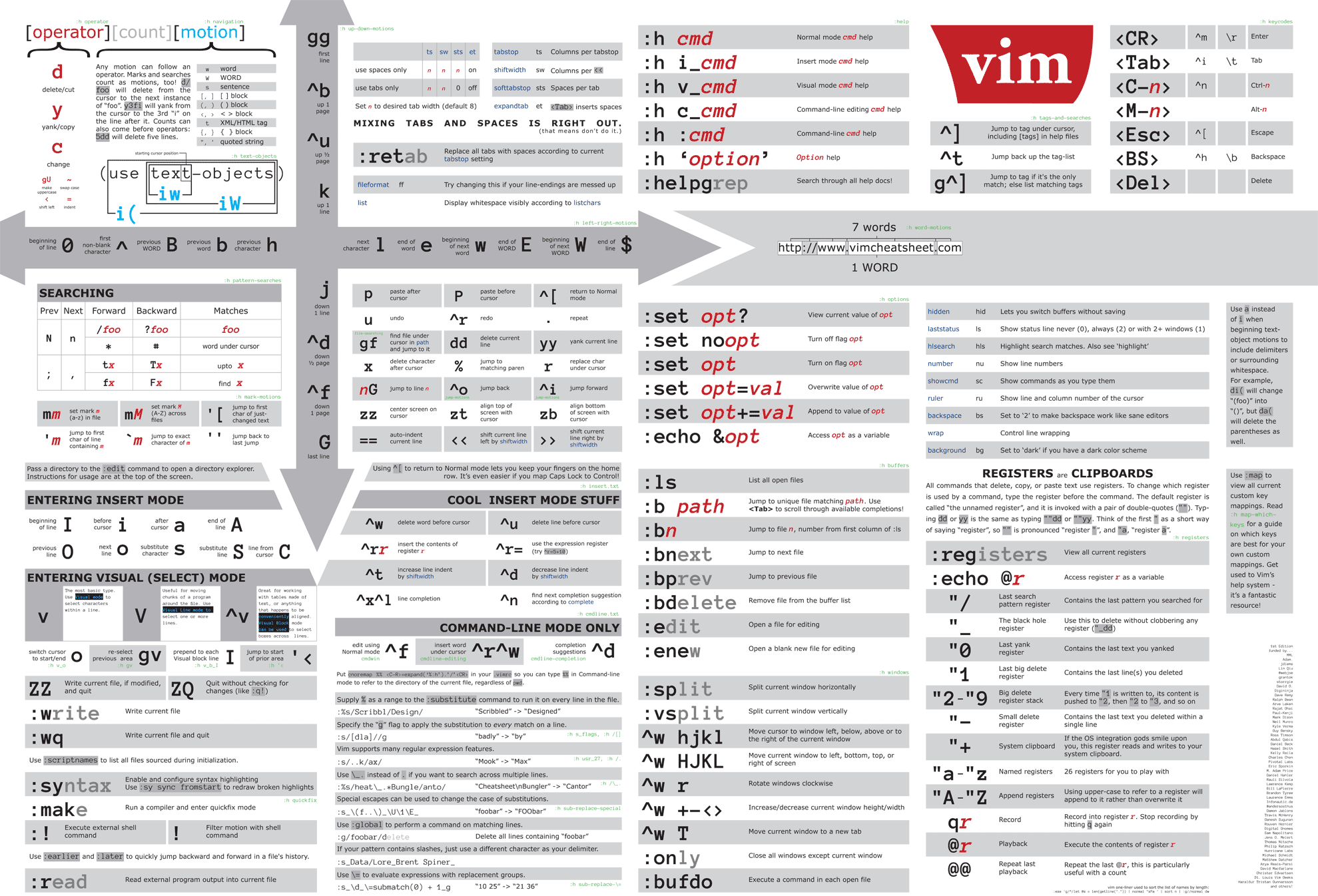
欢迎回到 探索 Vim 插件系列 !在本系列中,你将学习如何发现很棒的 Vim 插件以及如何掌握它们,从而每天提高工作效率。而今天,轮到我的最爱之一了: targets.vim 。


Vim 编辑器的优势和劣势,我已经了解了不少。作为开发者,使用 Vim 要比其它编辑器要快一些,看起来确是如此。然而,我正在使用 Vim 做一些基础编辑,却时常感到效率慢了 10 倍不止。
当谈及编辑速度时(你应该更多地关注于此),我们把重点放在两个方面:
交替地使用左右手,是操作键盘 最快 的方式;
尽可能不碰鼠标,是追求极致速度的唯二法门。移动手腕,抓取鼠标,移动鼠标,手指返回键盘……需要花费极长时间(更别说,通常你不得不低头盯着键盘,确保手指放到了正确的位置)。,
我有以下两个例子,来说明使用 Vim 为何没有体验到效率提升。
注意
Since they've moved to oni2, that changed lots of things, I'm gonna flag this post as obsolete. DON'T READ!
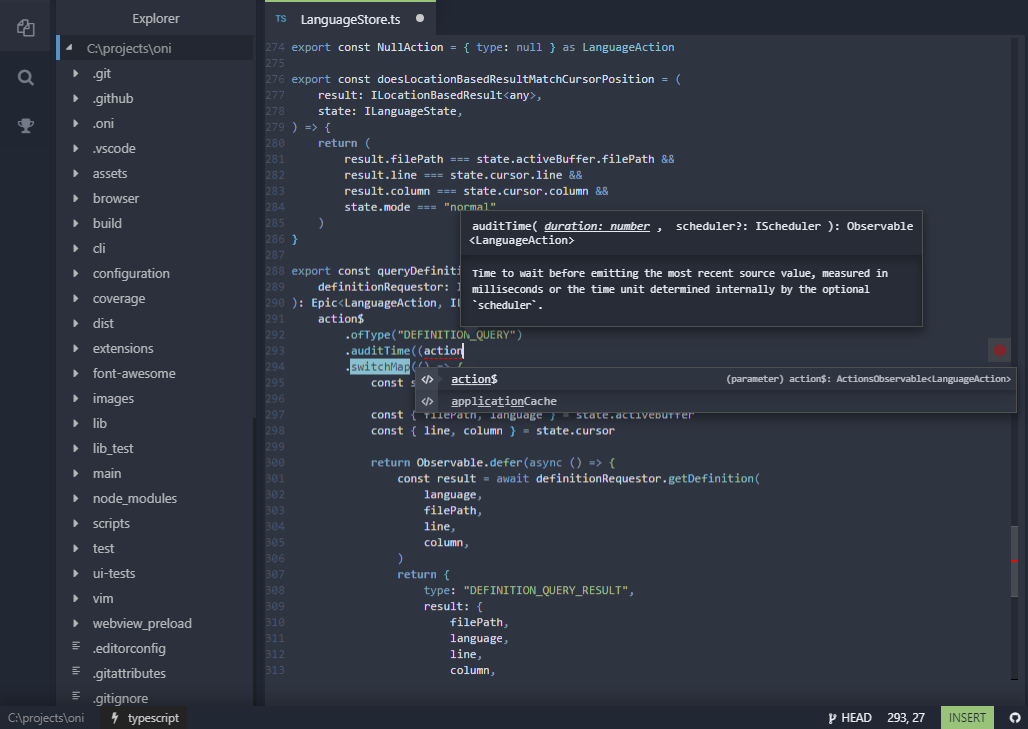
本来对这次版本更新还有些不以为然:为何不把精力放在完善 Language Server Protocol 支持,而跑去写什么新手教程呢?直到今天尝试了下教程,又看了文字版更新内容,才明白过来:Oni 编辑器正朝着我期待的方向前进!
来看看本次更新的两个重要功能: