【译】Atom 新的并发友好型 buffer 实现
Atom 的一些功能依赖于缓冲区(buffer)内容基础上的运算(可能会花费很长时间),但是直到最近,还只能从运行在主线程上的 JavaScript 访问缓冲区的文本。这使得无法在所有情况下保证 Atom 的响应能力,尤其是在编辑较大文件时。
这种情况随着 Atom 1.19 的发布而有所改变,该版本通过使用 C++ 实现的文本存储极大地提高了并行处理能力。这项新设计为性能和可伸缩性提供了诸多好处,其中主要优点之一是 worker 线程可以读取之前缓冲区的快照(snapshot),而不会阻塞主线程上的写入。在这篇文章中,我们将深入介绍 Atom 的文本存储新方法,然后探讨由此带来的首批优化。
文档目录
分层(layering)的变动
Atom 新的 buffer 实现,关键思想是将文本缓冲区内容分为两个主要状态。首先,有 基本文本(base text) ,对应于最近从磁盘读取或写入的文档版本。基本文本是不可变的,并存储在单个连续分配的内存块中。叠加在基本文本之上的是 未保存更改(unsaved changes) ,存储在被称为 补丁(patch) 的单独稀疏数据结构中。要记录编辑内容,无需将缓冲区的所有内容在内存中腾来挪去,我们只需对 patch 进行更改即可。
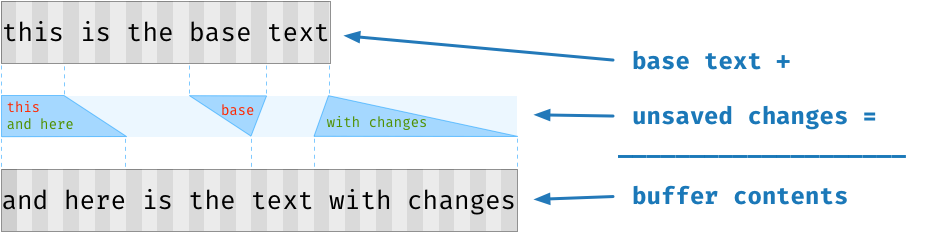
实际上,任何时刻都可能存在多个层级的 patch。最顶层的 patch 始终是可变的,但是我们可以冻结最顶层的 patch 并将一个新的 patch 推到栈顶,来创建当前缓冲区内容的只读快照(snapshot)。编辑操作将流向这个新的 patch,直到不再需要快照为止,此时最顶层的 patch 可以被合并到上一层的 patch 之中。
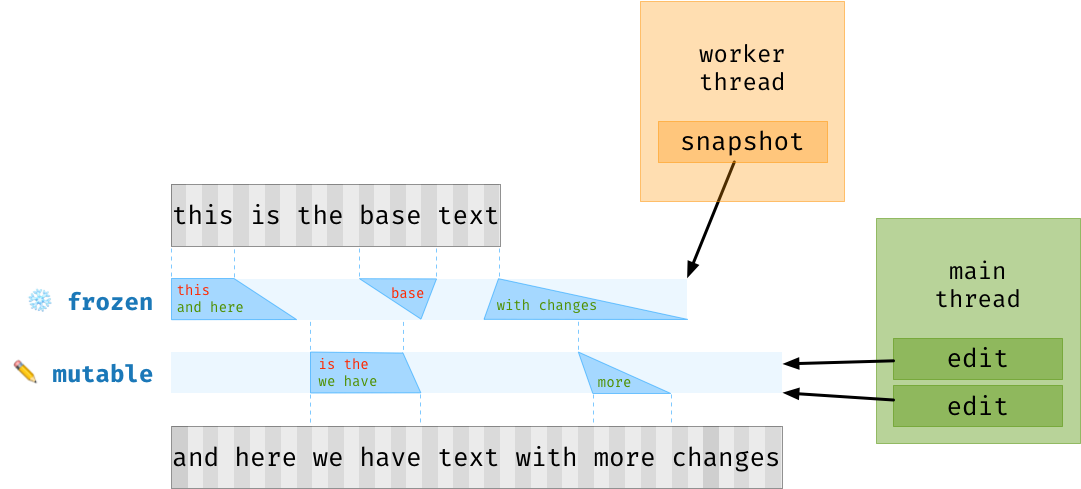
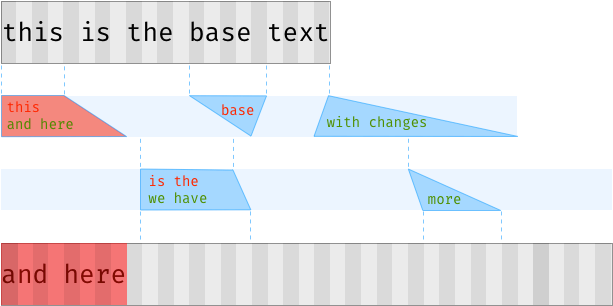
要读取缓冲区状态,我们遍历连续的“块(chunk)”,其中每个块对应于一次更改,来自于一个分层补丁或基本文本的数组切片。
Patch 的数据结构
整个系统的核心是 Patch 数据结构,它描述了如何将一系列文本更改应用于某些输入以产生新的输出。基本上,它与你运行 diff 所获得的信息相同,但它不是将两个缓冲区进行比较而产生,而是通过将一系列编辑组合在一起来逐步构造的。
存在的问题
为了更好地理解 Patch 要解决的问题,请考虑以下示例。我们从包含 xxxx 内容的缓冲区开始,然后执行以下插入操作:
insert B @ 2->xxBxxinsert C @ 4->xxBxCxinsert A @ 1->xAxBxCx
以字符敏感的差异比较形式(character-wise diff),总结一下我们所做的更改,如下所示:
[ {oldRange: [1, 1], oldText: '', newRange: [1, 2], newText: 'A'}, {oldRange: [2, 2], oldText: '', newRange: [3, 4], newText: 'B'}, {oldRange: [3, 3], oldText: '', newRange: [5, 6], newText: 'C'} ]
此差异中的每个条目都有一个 oldRange 键,它不理会 patch 中的任何其它更改。例如,插入 C 的条目其 oldRange 值为 [3, 3] ,它排除了插入 A 和 B 的影响。与之相反,每个条目中的 newRange 都反映了 patch 中其它更改所带来的偏移影响。例如,插入 C 的条目其 newRange 值为 [5, 6] ,就考虑了缓冲区插入的 A 和 B 。
如果没有进一步处理,则无法从原始编辑流中获得这种总结摘要。我们来看一下索引 4 处的 C 插入。该索引已经考虑到之前 B 插入的影响,但没有顾及到 A , A 在 空间 偏移方面在 C 前面,但 时间 顺序上则在 C 之后。想要在以上所示的差异比较中构建 oldRange 和 newRange ,我们需要了解每个更改彼此之间的空间关系,这与它们的时间顺序无关。
原生的解决方案
这个问题的一个简单解决方案是,将每次更改都存储到一个列表中,每次更改分别包含 oldText , newText 和 distanceFromPreviousChange 。通过遍历已有更改来确定此列表中每个新条目的插入位置。根据以上示例中的插入操作,这是更改列表现在的样子:
assert.deepEqual(patch.changes, []) patch.splice(2, '', 'B') assert.deepEqual(patch.changes, [ {distanceFromPreviousChange: 2, oldText: '', newText: 'B'} ]) patch.splice(4, '', 'C') assert.deepEqual(patch.changes, [ {oldText: '', newText: 'B', distanceFromPreviousChange: 2}, {oldText: '', newText: 'C', distanceFromPreviousChange: 1} ]) patch.splice(1, '', 'A') assert.deepEqual(patch.changes, [ {oldText: '', newText: 'A', distanceFromPreviousChange: 1}, {oldText: '', newText: 'B', distanceFromPreviousChange: 1}, {oldText: '', newText: 'C', distanceFromPreviousChange: 1} ])
在我们的案例中, oldText 始终为空。因为我们仅执行了插入操作,但是通过指定 oldText 为非空值很容易表示删除或替换。一旦我们创建了更改列表,就可以通过迭代列表,从之前更改的范围确定 oldRange 和 newRange 的开始位置,最终产生需要的编辑摘要。
Splay trees
上述方法的问题在于,在列表中插入一项更改可能需要我们检查所有其它更改,这会产生 \(O\left(n^2\right)\) 的时间复杂度。
在产品实现中为了确保良好性能,我们通过使用 splay tree 而非简单列表将时间缩短到 \(O\left(n\cdot\log_2n\right)\) 范围内。Splay tree 是二进制搜索树(binary search tree)的一种版本,实现起来非常简单,而且具有“自我优化(self-optimizing)”的超酷特性。这意味着在查询和搜索时,它们会自动调整其结构,以便访问最近访问的节点附近的节点时更加方便。对于随机化的工作负载,此特性没有帮助。但是对于局部高密度的工作负载(例如文本编辑器)而言,这种自我优化的特性非常有用。
Splay tree 的原理非常简单。每当一个节点被访问时,都会通过一系列特殊的指针旋转(称为 splay )将其旋转到树的根部。这种旋转(splaying)不仅将节点移动到树根,而且还减少了节点附近树的深度,从而确保下次我们访问附近的节点时,更靠近树根,因此查找速度更快。
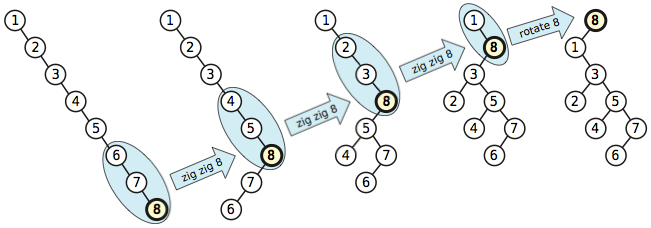
值得注意的一点是 \(O\left(n\cdot\log_2n\right)\) 是 摊销范围 。单次操作的成本可能高达 \(O\left(n\right)\) ,但我们可以通过重组树降低后续操作成本来补偿。事实上,情况还好。通常,单次线性时间(linear-time)操作不会引起性能问题。只有当批量执行 多个 线性时间运算时,时间复杂度才变成二次方,这正是 splay tree 帮助我们避免的情况。
如果你想了解有关 splay tree 的更多信息, 来自 MIT 的 David Karger 的课程 是很棒的介绍。
为我们的用例增强 splay tree
理论上来说,splay tree 始终被表示为键和值之间的简单有序映射。对于我们的 Patch 来说,我们需要解决一个更复杂的问题:我们的树需要在新旧坐标空间里维护每个节点的位置,以便每当发生新的更改时,我们都可以有效地更新所有后续节点的位置。为此,我们要避免将每个节点与常量键相关联,而是将他们与相对表达值相关联,该表达值代表节点在新旧坐标空间里与其 左祖先 的距离。
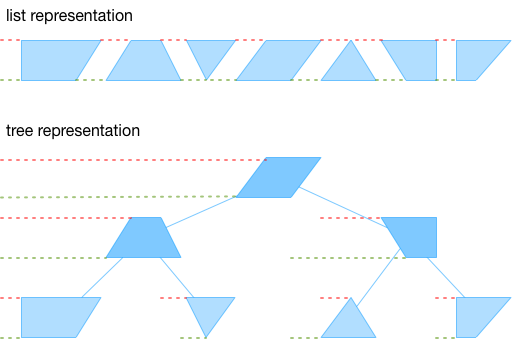
在上图中,每个更改都显示为梯形,以图形方式表示替换字符对空间偏移的影响。在前面提到的列表表示中,在两个坐标空间中,与前一个更改的距离始终相同,因为任何两个更改之间的文本均保持不变。在 splay tree 版本中,每个更改都存储了与其左祖先的距离,这汇总了本次更改左边整个子树的空间偏移影响。上图每个深色节点都包含了它们左边子树的更改,亦即每个坐标空间里与其左祖先的距离的值都不相同。要把相对距离转换为绝对位置,我们在两个坐标空间里执行一次累加计算,因为 splay tree 从树根降格为了树叶。
要插入新更改,我们将最靠近替换范围的现有更改旋转(splay)一下。旋转(splay)操作重新排列指针之时,我们根据本地可用信息更新与每个节点左祖先的距离。一旦上下方的节点旋转到树的根部,它们 之间 的任何节点都将被我们插入的更改所包围,这意味着它们可以被删除。然后,我们插入新更改,将其与树根上的一至两个节点合并,这取决于它是否与它们重叠。

对于 patch 结构而言,旋转(splaying)并不仅仅是将树保持平衡的机制。事实上,我们依赖于将节点移至树根的功能,以便将新的更改拼接到结构体中。如果使用严格平衡的数据结构(如红黑树),则在不违反关键不变性的情况下,以这种方式将节点旋转到根节点将更加困难。
值得注意的是,在以上所有示例中,为清晰易懂起见,我们都使用了纯数值表示位置和距离。实际上,这些值都是由行和列组成的二维向量表示的。这增加了一些复杂性,但是基本思想保持不变。还值得注意的是,此结构还有一些超出本文所讲的 buffer 实现范畴的功能。最初我们创建它来汇总各项事务中所发生的所有变化,以便 将差异结果通知更改监听器(change listener) ,并 以最紧凑的方式保存撤销堆栈(undo stack) 。我们还使用 patch 来 索引 buffer 与屏幕坐标间的转换 ,以完成展示向(presentation-oriented)事务如软换行(soft-wrapping)和代码折叠(code folding)的切换。这是一段 复杂的代码 ,但是我们从中受益良多。
一些初始优化
就 Atom 的整体效率而言,将 buffer 实现转移到 C++ 本身就是一个胜利。JavaScript 可以相当快,但是根本上它还是一种脚本语言,具有不可避免的开销。通过在 C++ 中实现缓冲区,我们消除了 JS 的开销,并实现了所需的效率最大化目标。通过简化堆栈并在频繁调用的代码中分配更少的短期对象,我们还减轻了 V8 垃圾回收器的压力。但是这些改进仅仅是开始,新实现的真正价值在于其分层设计所带来的优化。
高效备份 unsaved changes
去年一月,我们刚刚完成了另一项改进,使得 Atom 可以处理更大的文件以消除那令人沮丧的瓶颈。编辑大文件时最大的烦恼之一是,将大缓冲区未保存状态定期写入磁盘所带来的开销。只要大小足够,即便收集缓冲区的内容异步写入,也会带来可感知的卡顿。尽管可以巧妙地使用 requestIdleCallback 和输出流(output stream)来应付,我们依旧担心每分钟多次写入大量数据所带来的能效影响。我们考虑新的 buffer 实现已经有一段时间,进行高效的后台保存也是构建该实现很好的初始动机。
为了崩溃恢复之目的,我们只关心未保存的更改,这恰恰是新的 buffer 实现极容易提供的。现在,我们无需检出缓冲区的全部内容,只要 将所有未完成的层级组合成一个 patch ,并将其与基本文本的指纹(digest)一起序列化(serialize)到磁盘。其写入的数据量与更改数量(而非文件大小)成正比,因此在大多数情况下效率更高。有时可能仍需要处理有数十兆未保存更改的文件,但是这种情况很少见。
异步保存
在 1.19 版本之前,在 Atom 中保存缓冲区是 同步 操作 😱。这是因为写入文件的代码早于 Electron 的诞生,并且在那时,从基于浏览器的桌面应用中执行异步 I/O 并不像现在这样简单。令人高兴的是,新的 buffer 实现为我们提供了以优雅的方式最终解决此问题的机会。现在,将缓冲区内容从 UTF-16 转换为用户所需的编码并将其写入磁盘, 完全使用 C++ 在后台线程上执行 。在开始保存之前,我们将创建一个快照,以便即使在保存缓慢(例如使用网络驱动器)时,用户也可以自由进行其它更改。
自动补全时在后台进行子序列匹配
默认情况下,Atom 的自动补全从打开的缓冲区提供单词建议,这是通过与光标前面的字符的子序列匹配来完成的。例如,键入 bna 将提供 banana , bandaid 以及 bandana 作为建议。然后,我们根据匹配质量评分将单词建议进行排序。
在 Atom 1.22 版之前,我们通过为每个缓冲区维护唯一的单词列表,并在主线程上运行 JavaScript 以匹配,评分和排序建议来实现此功能。尽管对于大多数文件来说,这还可以,但是随着文件大小的增加,单词列表开始占用大量内存,并且主线程上的建议匹配可能会可感知地阻塞 UI。
得益于新的 buffer 实现,我们在 Atom 1.22 特性中推出了一项新的自动补全功能,利用快照(snapshot)来完成相同的工作,而没有内存开销,也不会威胁 Atom 的响应能力。现在,大多数的繁重工作都由新的 TextBuffer.findWordsWithSubsequence 方法完成,它在后台线程中执行 匹配,评分和排序 。这意味着我们可以在每次击键后立即开始搜索建议,而其它工作仍在主线程中运行。等到下一帧重绘时,通常建议已经可用,但是在搜索建议时我们一帧都不会延迟。在极少数情况下,单词建议需要花费比一帧更长的时间来计算,那我们将在下一帧中呈现它们。
要立即尝试新的自动补全,请 下载 1.22 Beta ,在“设置”视图中导航至 autocomplete-plus ,将选项 Default Provider 切换为 Subsequence 。

如果使用新的自动补全时你遇到任何问题,请告诉我们。如果一切顺利,它将是 Atom 1.23 中包含的唯一默认自动补全。
未来回报
新的 buffer 实现为将来的诸多改进奠定了基础。短期内而言,能够在 worker 线程中执行非阻塞读取,将帮助我们改善许多领域的响应能力,其中包括一些尚未探索领域。
从长期来看,将 buffer 实现切换到 C++,也为我们移植其它子系统打开了大门。我们正在逐步构建一个名为 superstring 的原生库,该库在 Atom 的核心实现了多个性能关键组件,例如本文中描述的 patch 和文本存储数据结构。我们通过 V8 嵌入 API 将该库与 JavaScript 联结,但它也有 现成的 Emscripten 绑定 ,可在 Electron 之外使用。现在, superstring 中与 buffer 相关的关键代码已完成,我们可以将需要访问 buffer 内容的性能关键代码逐步移植过去。
需要明确的是,JavaScript 的易用性和灵活性是一项巨大的优势。因此,放弃这些优势以换取 C++ 原生性能之前,我们将三思而后行。但是,我们希望在本文中表明一点:JavaScript 的局限性并不会成为在 Atom 中提供出色性能的根本障碍。
引用资源:https://blog.atom.io/2017/10/12/atoms-new-buffer-implementation.html
文章链接:https://macplay.github.io/posts/atoms-new-concurrency-friendly-buffer-implementation/
发布/更新于:
版权声明:如无特别说明,本站文章均遵循 CC BY-NC-SA 4.0 协议,转载请注明作者及出处。