【译】重新实现 Text Buffer
Visual Studio Code 1.21 发行版包含一个全新的 text buffer(文本缓冲区)实现,无论在速度还是在内存使用方面,该实现都更加出色。在本文中,我想讲一下我们是如何选择/设计数据结构和算法以实现这些提升的。
文档目录
关于 JavaScript 程序性能的讨论,通常涉及应该使用多少原生代码来实现的问题。对于 VS Code 的 text buffer,一年多以前就有一些相关讨论。经过深入的研究,我们发现 text buffer 的 C++ 实现可以节省大量内存,但是却并没有看到所期望的性能提升。在原生代码和 V8 之间转换字符串的成本很高,在我们的案例中,这损害了使用 C++ 实现 text buffer 所获得的性能提升。我们将在本文结尾处对此进行更详细的讨论。
无法使用原生代码,我们必须另行寻找改善 JavaScript/TypeScript 代码的方法。我们看到一些鼓舞人心的博文,比如 Vyacheslav Egorov 的这篇:在 文章里 他演示了如何将 JavaScript 引擎推到极限,并压榨出尽可能多的性能。即便不使用底层引擎优化技巧,我们也可以通过更合适的数据结构,更快的算法来将速度提升一至多个数量级。
之前的 text buffer 数据结构
编辑器的思维模型是基于行的。开发者逐行读取和写入源码,编译器提供基于行/列的诊断, 堆栈跟踪包含了行号,标记引擎逐行运行,等等。尽管很简单,但从我们启动 Monaco 项目以来,支持 VS Code 的 text buffer 实现并没有太大变化。我们使用了文本行数组,效果还不错,因为一般来说文本文档相对较小。当用户键入内容时,我们在数组中找到修改的行,并将其替换。插入新行时,我们将新的行对象拼接到行数组中,JavaScript 引擎将为我们完成繁重的工作。
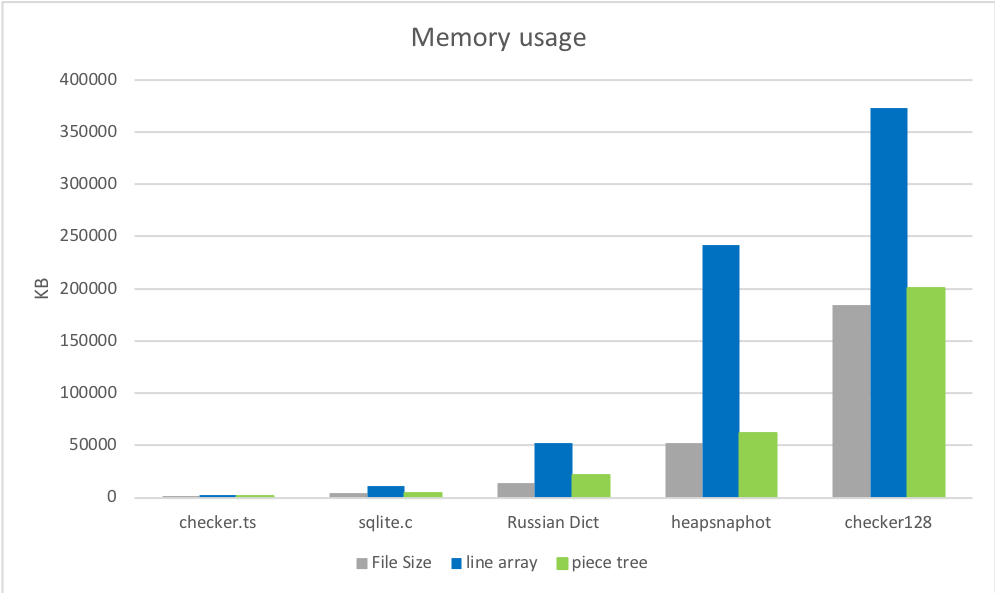
但是,我们一直收到打开某些文件会导致内存不足 VS Code 崩溃的报告。例如,有用户无法打开 35 MB 的文件 。其根本原因是文件行数太多,共 1370 万行。我们需要为每行创建一个 ModelLine 对象,每个对象占用约 40-60 字节,因此,行数组使用了大约 600 MB 的内存来存储文档。这大约是初始文件大小的 20 倍!
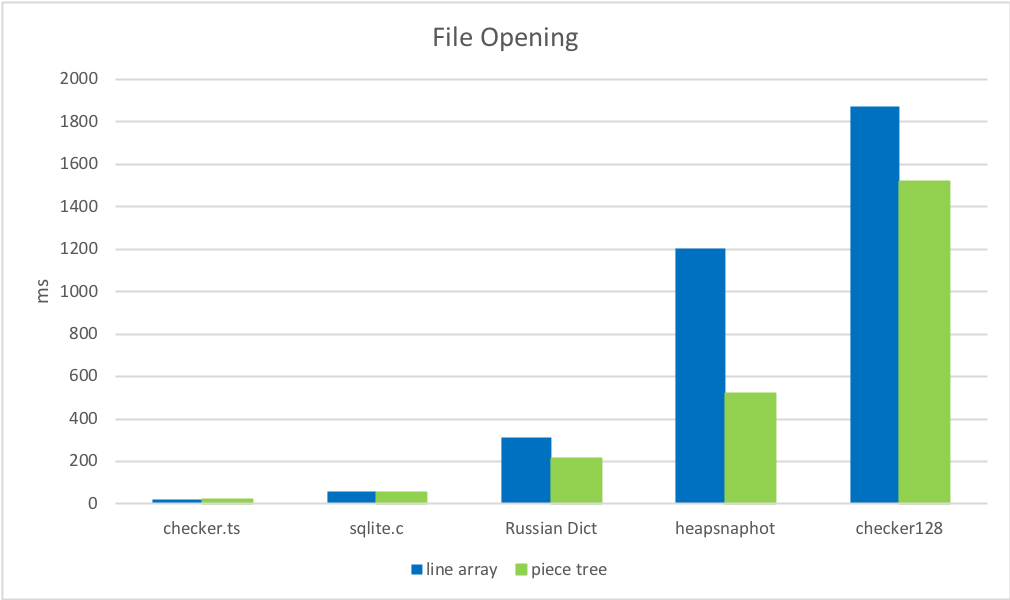
文本行数组的另一个问题是打开文件的速度。要构建行数组,我们必须按换行符拆分内容,以便从每行获得一个字符串对象。拆分过程本身会损害性能,你将在下面的基准测试中看到这种情况。
寻找新的 text buffer 实现
旧的行数组需要花费大量时间来创建,并消耗大量内存,但是它提供了快速的行查找。在理想情况下,我们应只需存储文件的文本,而无需存储其它元数据。因此,我们开始寻找较少元数据的数据结构。在审视了各种数据结构之后,我发现 piece table 可能是一个不错的开始。
使用 piece table 来避免过多的元数据
Piece table 是一种数据结构,用于表示对文本文档的一系列编辑(TypeScript 源码):
class PieceTable { original: string; // original contents added: string; // user added contents nodes: Node[]; } class Node { type: NodeType; start: number; length: number; } enum NodeType { Original, Added }
当文件加载之后,piece table 的 original 字段将包含整个文件内容, added 字段为空,还有一个 NodeType.Original 类型为单节点。当用户在文件末尾键入时,我们把新内容附加到 added 字段,并在节点列表末尾插入一个新的类型节点 NodeType.Added 。同样地,当用户在节点中间进行编辑时,我们将拆分该节点并根据需要插入一个新节点。
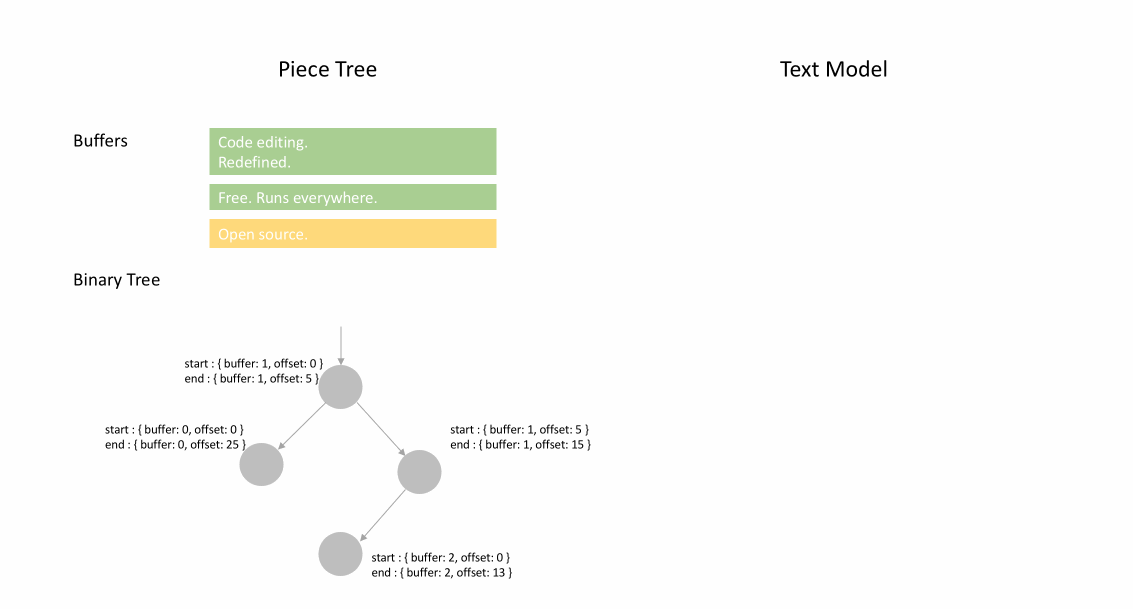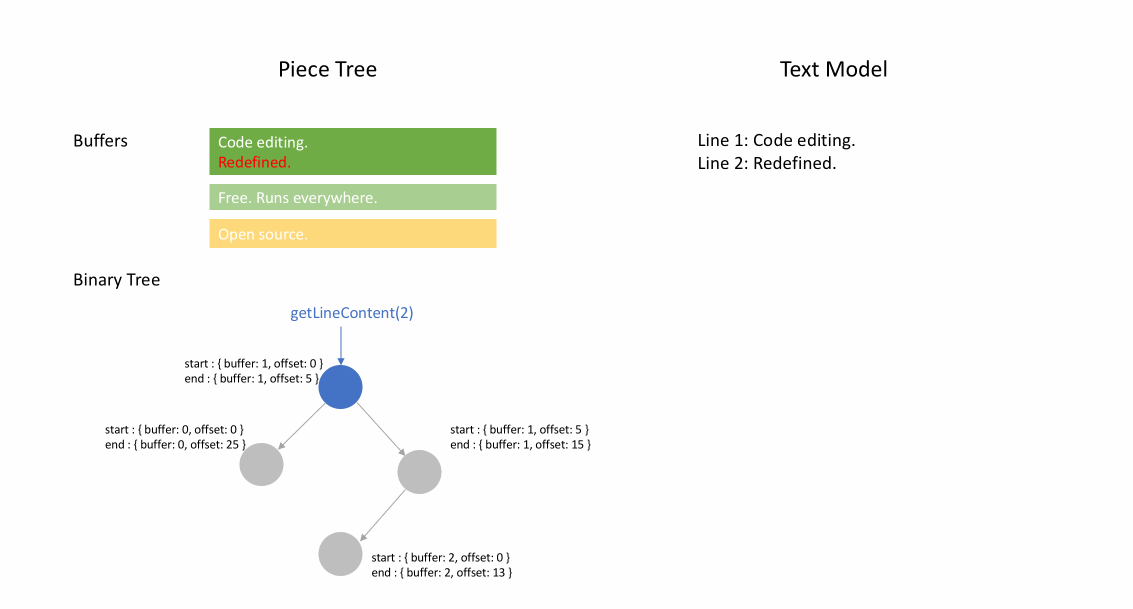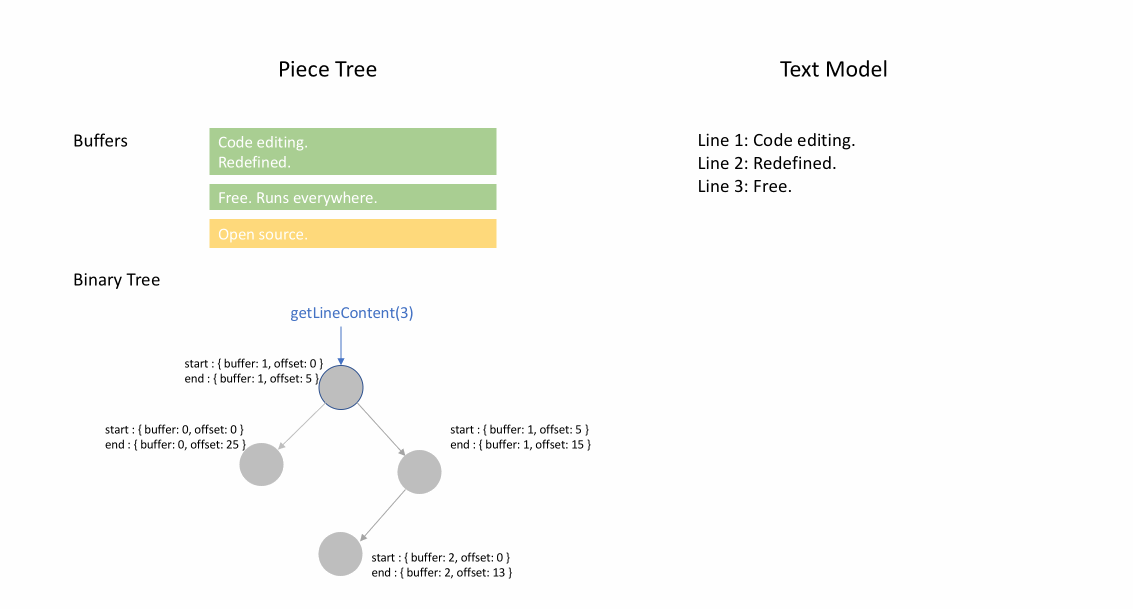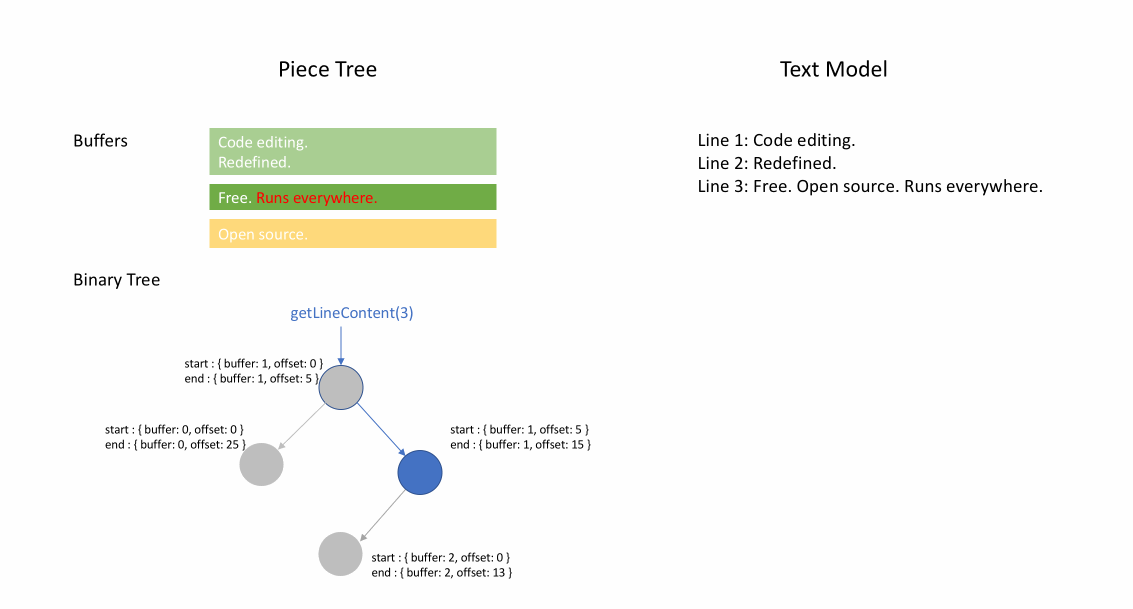
下面的动画展示了在 piece table 结构中如何逐行访问文档。它有两个 buffer 缓冲区( original 和 added ),和三个节点(因为在 original 内容中间进行了插入操作)。
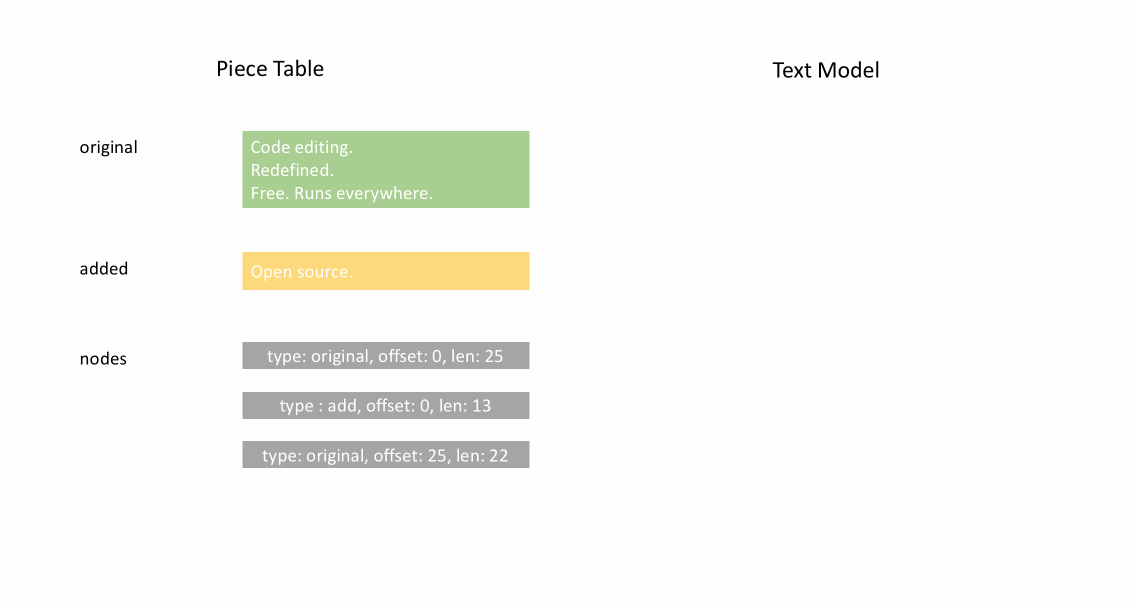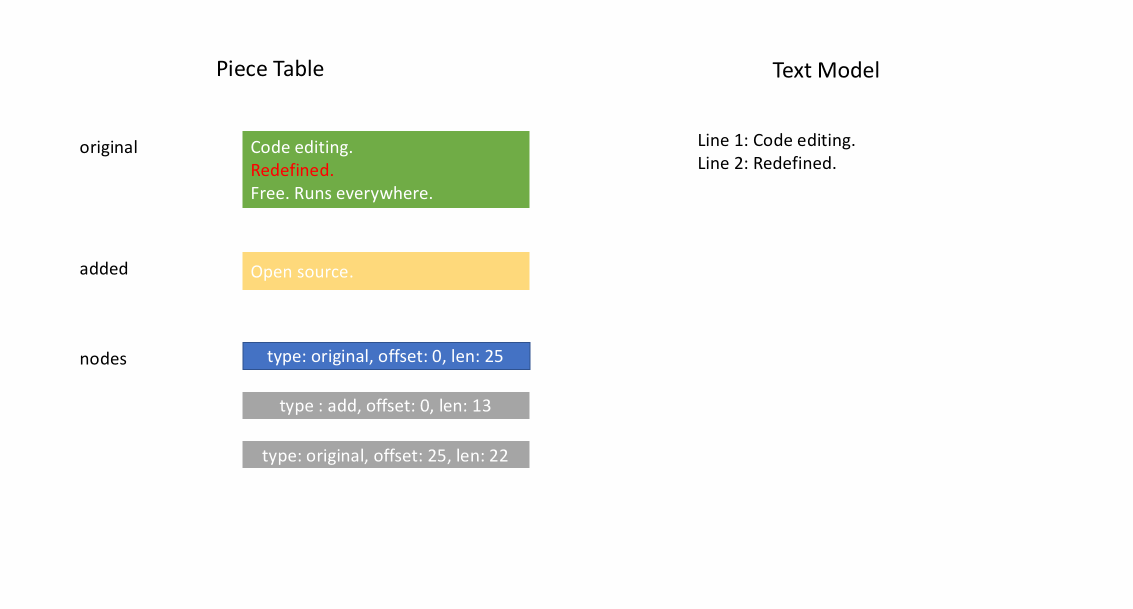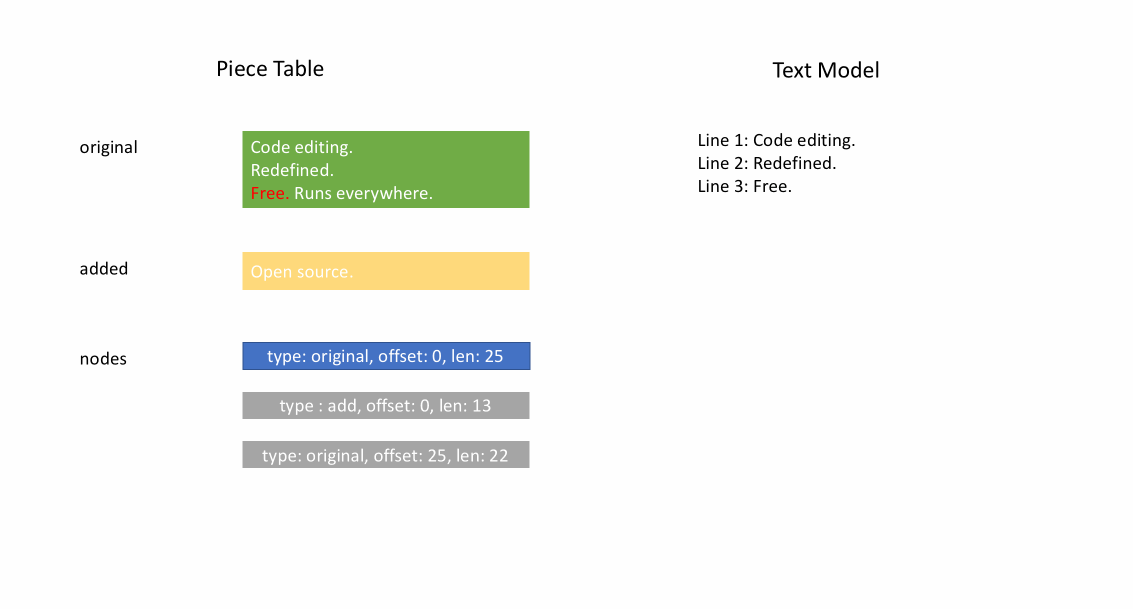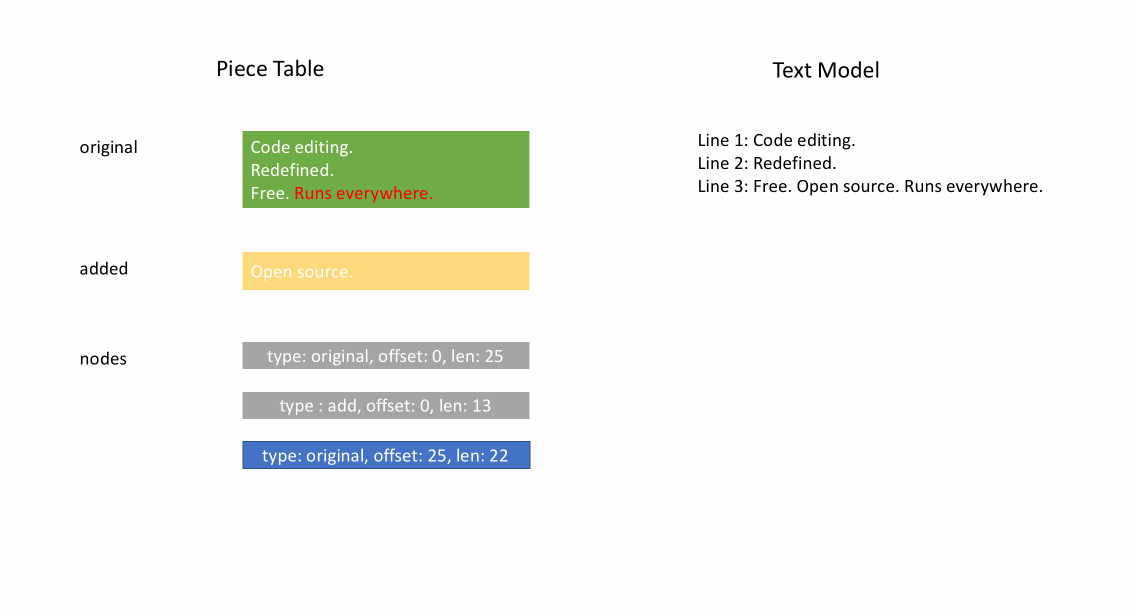
Piece table 的初始内存占用接近于文档大小,修改所需的内存与编辑/添加的文本数量成正比。因此,通常来说 piece table 可以充分利用内存。然而,低内存占用的代价是访问逻辑行很慢。例如,如果要获取第 1000 行的内容,唯一的方法是从文档开头遍历每个字符,找到前 999 个换行符,然后读取每个字符直到下一个换行符。
使用缓存加速行查找
传统的 piece table 节点仅包含偏移量,但是我们可以添加换行符信息以更快地查找行内容。存储换行位置的直观方法是,存储节点文本中遇到的每个换行的偏移量。
class PieceTable { original: string; added: string; nodes: Node[]; } class Node { type: NodeType; start: number; length: number; lineStarts: number[]; } enum NodeType { Original, Added }
例如,如果想要访问指定 Node 实例中的第二行,则可以读取 node.lineStarts[0] 和 node.lineStarts[1] ,这将给出该行开始和结束处的绝对偏移量。我们已经知道节点有多少个换行符,因此访问文档中随机行变得很容易:从第一个开始读取每个节点,直到找到目标换行符为止。
算法依旧简单,但工作的比以前更好。现在我们可以跳过整个文件块(chunks),而无需逐个字符遍历文本。稍后会看到,我们可以做得更好。
避免字符串合并陷阱
Piece table 包含两个缓冲区(buffer),一个用于从磁盘加载的原始内容,另一个用于用户编辑。在 VS Code 中,我们使用 Node.js 的 fs.readFile 加载文本文件,以 64 KB 的块大小(chunk)为单位交付内容。因此,当文件很大(例如 64 MB)时,我们将收到 1000 个文件块。接收到所有块后,我们把他们合并为一个大的字符串,然后将其存放到 piece table 的 original 字段中。
听起来很合理对不对?直到 V8 成为了绊脚石。当尝试打开一个 500 MB 的文件我遇到了异常,因为我所使用的 V8 版本,支持的最大字符串长度为 256 MB。在将来的 V8 版本中,该限制将提高到 1 GB,但这并不能真正地解决问题。
与其保存 original 和 added 缓冲区,不如保存那一堆缓冲区(buffer)的列表。我们可以尝试让列表尽量简短,或者从 fs.readFile 得到启发,避免任何字符串合并。每次从磁盘获取到一个 64 KB 的块,我们将其直接放到 buffers 数组中,并创建一个指向该缓冲区的节点。
class PieceTable { buffers: string[]; nodes: Node[]; } class Node { bufferIndex: number; start: number; // start offset in buffers[bufferIndex] length: number; lineStarts: number[]; }
使用平衡二叉树加速行查找
没有字符串合并碍手碍脚,现在我们可以打开大文件了,但这又导致了另一个潜在的性能问题。比如我们加载了一个 64 MB 的文件,piece table 将有 1000 个节点。即便在每个节点中缓存换行位置,我们仍然不清楚某个绝对行号处在哪个节点中。要获取某一行的内容,我们不得不翻遍所有节点以找到包含该行的节点。在本案例中,我们必须迭代多达 1000 个节点,具体取决于要查找的行号。因此,最糟糕的情况下,时间复杂度为 \(O\left(N\right)\) (N 为节点数)。
在每个节点中缓存绝对行号,然后针对节点列表采用二分法(binary search)查找,将会加快查找速度。但是,每次修改一个节点,我们将不得不访问之后的所有节点,并对其应用行号差值。这是条不归路,但二分法查找的想法不错。要达到相同的效果,我们可以利用平衡二叉树(balanced binary tree)。
现在,我们必须确定使用哪些元数据作为树节点的键方便比较。如前所述,在文档中使用节点的偏移量或绝对行号,将使编辑操作的时间复杂度达到 \(O\left(N\right)\) 。如果我们希望时间复杂度为 \(O\left(\log_2N\right)\) ,则需要只与子树相关的东西。因此,当用户编辑文本时,我们重新计算已修改节点的元数据,然后将更改从父节点一路应用到根节点。
如果一个节点 Node 只有四个属性( bufferIndex , start , length, lineStarts ),则需要花费数秒才能找到结果。为了更快些,我们还可以存储文本长度和节点左子树的换行符数。通过这种方式,从根节点按偏移量或行号进行搜索将非常高效。存储右子树的元数据也可以,但是无需同时缓存两者。
现在的类如下所示:
class PieceTable { buffers: string[]; rootNode: Node; } class Node { bufferIndex: number; start: number; length: number; lineStarts: number[]; left_subtree_length: number; left_subtree_lfcnt: number; left: Node; right: Node; parent: Node; }
在所有不同类型的平衡二叉树中,我们选择 红黑树 是因为它更“易于编辑”。
减少对象分配
假如在每个节点中存储换行偏移量,那每次更改节点时,我们可能都必须更新换行偏移量。例如,如果有一个包含 999 个换行符的节点,该 lineStarts 数组有 1000 个元素。如果我们平均分割节点,那么将创建两个节点,每个各有一个包含约 500 个元素的数组。由于不是直接在线性内存上进行操作,因此将数组拆分为两个比仅移动指针的开销更大。
好消息是,piece table 中的缓冲区要么是只读的(original buffers),要么是仅追加的(changed buffers),因此缓冲区中的换行符不会变动。 Node 仅需简单地在其对应缓冲区上保存两个对换行偏移量的引用即可。我们做的越少,性能就越好。我们的基准测试表明,这项变动使 text buffer 操作快了三倍。具体实现细节稍后再讲。
class Buffer { value: string; lineStarts: number[]; } class BufferPosition { index: number; // index in Buffer.lineStarts remainder: number; } class PieceTable { buffers: Buffer[]; rootNode: Node; } class Node { bufferIndex: number; start: BufferPosition; end: BufferPosition; ... }
Piece Tree
我很想将这个 text buffer 实现称为“针对行模型优化的使用红黑树的多缓冲区的 piece table(Multiple buffer piece table with red-black tree, optimized for line model)”。但在我们的每日例会中,每人只有 90 秒分享他们所做的事情,多次重复这个长名字并不明智。因此,我只是简单地称为“ piece table ”,还算名符其实。
对这种数据结构理论上的了解是一回事,而实际性能则是另一回事。你使用的语言,代码运行的环境,客户端调用 API 的方式以及其它因素,可能会对结果有显著影响。基准测试可以提供全面的信息,因此我们针对原有的行数组实现和 piece table 实现,分别使用小/中/大型文件进行了测试。
准备工作
为了结果的真实有效,我在网上找了一些现实中的文档:
checker.ts - 1.46 MB,26k 行
sqlite.c - 4.31 MB,128k 行
Russian English Bilingual dictionary - 14 MB,552k 行
并手动创建了几个大文件:
刚打开 VS Code Insider 时的 Chromium 堆栈快照 - 54 MB,3M 行
checker.ts X 128 - 184 MB,3M 行
3. 编辑
我模拟了两个工作流程:
在文档中的随机位置进行编辑
按顺序键入
我试图模仿这两种情况:对文档进行 1000 次随机编辑或 1000 次顺序插入,然后查看每个 text buffer 需要多少时间:
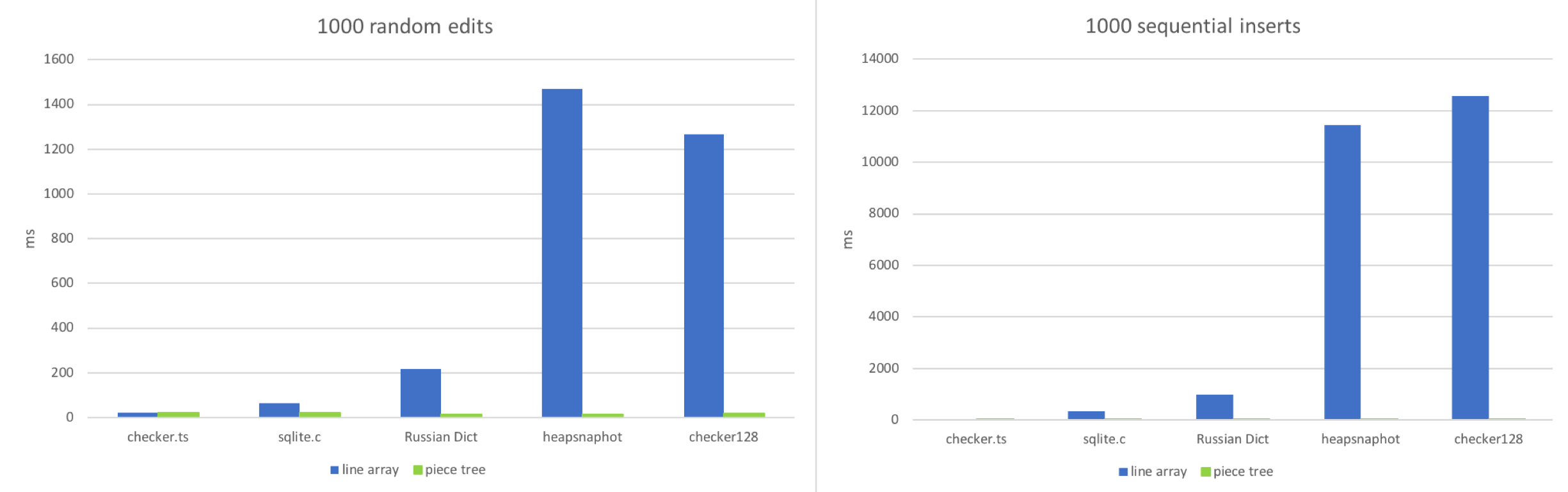
不出所料,当文件非常小时,行数组获胜。在一个小的数组中访问随机位置,并调整约 100~150 个字符长度的字符串时,这确实非常快。但当文件包含多行(100k+)时,行数组开始阻塞。大文件中的顺序插入使这种情况变得更糟,因为 JavaScript 引擎不得不做大量工作以便调整大数组的大小。Piece table 的表现则稳定得多,因为每次编辑只不过是一次字符串附加和几个红黑树操作而已。
4. 读取
对于 text buffer,调用最多的方法是 getLineContent 。视图代码,标记引擎,链接检测,以及几乎所有依赖文档内容的组件都要调用它。某些代码,如链接检测器遍历整个文件,而其它代码,如视图代码仅按顺序读取窗口中的行。因此,我针对不同场景对该方法进行基准测试:
进行 1000 次随机编辑,然后对所有行调用
getLineContent进行 1000 次顺序插入,然后对所有行调用
getLineContent进行 1000 次随机编辑,然后读取 10 个不同窗口内的行
进行 1000 次顺序插入,然后读取 10 个不同窗口内的行
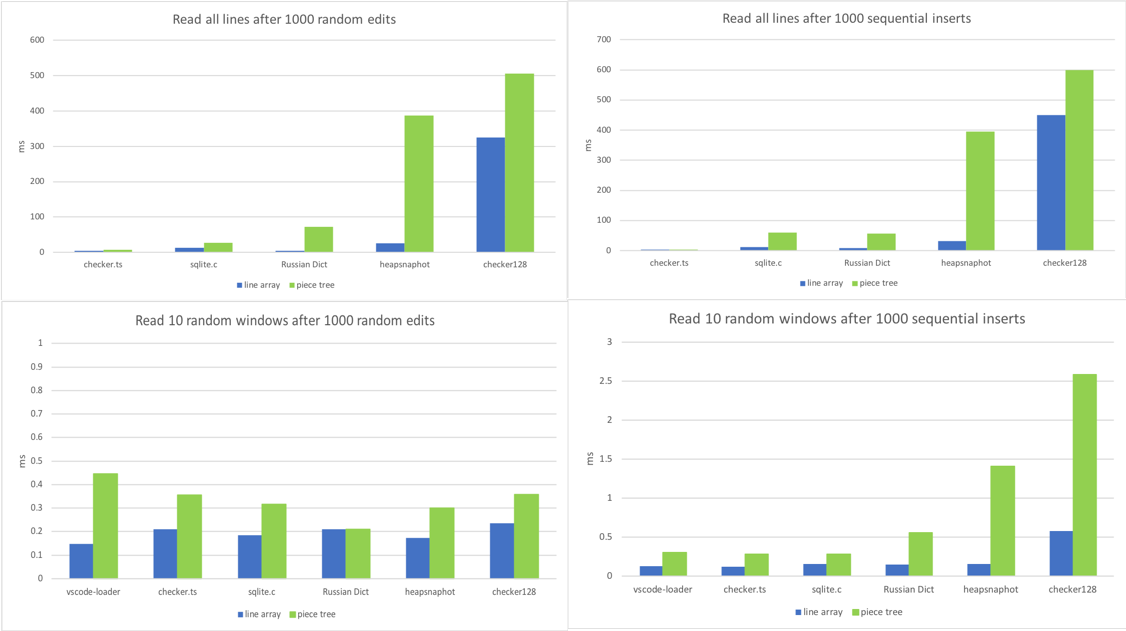
TA DA,我们找到了 piece tree 的阿喀琉斯之踵。一个大文件,经过 1000 次编辑,将会有成千上万个节点。即便查找一行的复杂度为 \(O\left(\log_2N\right)\) ( N 为节点数),也明显超过了行数组的 \(O\left(1\right)\) 。
进行上千次编辑是比较罕见的。在大文件中替换一个常用子字符串,你可能会见到这一场景。另外,我们正在谈论的是每个 getLineContent 调用所花费的时间,因此目前暂时不关心它。大多数 getLineContent 调用来自视图渲染和标记,行内容的后期处理也非常耗时。DOM 构建以及视窗的渲染/标记通常需要花费数十毫秒,其中 getLineContent 仅占不到 1%。无论怎样,我们总是可以考虑实现一个正常化步骤,如果满足某些条件(例如,节点数量很多),我们将重新创建缓冲区和节点。
结论与陷阱
在大多数情况下,除了基于行的查找之外,piece tree 的性能都优于行数组。
得到的教训
这次实现教给我最重要的一课是, 始终进行真实世界的分析 。每一次我都发现,对哪些方法调用最多的假设与现实不符。例如,当我开始实现 piece tree 时,我把重点放在优化三个原子操作:
insert,delete,search上。但是,当我将其集成到 VS Code 中时,那些都不重要。调用最多的方法是getLineContent。处理
CRLF或者混合换行符是程序员的噩梦 。对于每次修改,我们都要检查它是否分割了回车/换行(CRLF)序列,或者是否创建了新的 CRLF 序列。在树节点中处理所有可能的情况,进行几次尝试,直到找到正确快速的解决方案。GC(垃圾回收)可以轻易消耗你的 CPU 时间 。我们的文本模型曾假定缓冲区存储在数组中,我们频繁使用
getLineContent,尽管有时不是必需的。例如,如果只想知道某一行第一个字符的字符代码,我们先使用getLineContent,然后执行charCodeAt。使用 piece table 时,getLineContent将创建一个子字符串,检查过字符代码后那一行的子字符串被立即丢弃。这很浪费,我们正在努力采用更合适的方法。
为何不用原生代码?
文章开头我曾说过会回到这个问题。
太长不看: 我们尝试过,对我们来说没有用。
我们使用 C++ 实现了 text buffer,并使用原生 node 模块绑定将其集成到 VS Code 中。Text buffer 是 VS Code 中的常用组件,许多调用都是针对 text buffer 进行的。当调用和实现两者都使用 JavaScript 编写时,V8 可以内联许多此类调用。使用原生 text buffer 后,JavaScript <=> C++ 之间需要来回转换,考虑到来回转换的次数,这会把一切都减慢下来。
例如,VS Code 的 切换行注释 命令是通过遍历所有选定的行并逐一分析来实现的。该逻辑是用 JavaScript 编写的,针对每一行都会调用 TextBuffer.getLineContent 方法。而每一次调用,最终都得越过 C++/JavaScript 边界,并且必须返回一个 JavaScript string 对象,因为我们的所有代码均基于 JavaScript 构建的 API。
我们的选择很有限。在 C++ 中,我们要么针对每一次 getLineContent 调用都分配一个新的 JavaScript string 对象,这意味着把字符串拷贝来拷贝去,要么利用 V8 的 SlicedString 或者 ConstString 类型。然而,只有当底层存储也使用 V8 字符串时,才可以使用 V8 的字符串类型。但不幸的是,V8 的字符串并不是多线程安全的。
我们可以尝试通过更改 TextBuffer API 来克服这一点,或者将更多代码移植到 C++ 来避免 JavaScript/C++ 边界成本。但是,我们意识到我们同时在做两件事:我们使用不同于行数组的数据结构在重写 text buffer,同时还使用了 C++ 来编写而不是 JavaScript。因此,我们决定将 text buffer 的实现寄托于 JavaScript,而不是花半年的时间在我们不知道是否会得到回报的东西上,同时我们只改变数据结构和相关算法。我们认为,这是正确的决定。
未来的工作
我们仍然有一些使用场景需要优化。例如, 查找 命令当前是逐行运行,但这是不对的。当仅需要一个子字符串时,我们应该避免对 getLineContent 不必要的调用。我们将逐步改进并释出这些优化。即使没有这些优化,新的 text buffer 实现也可以提供比以前更好的用户体验,它现在已经是最新稳定版 VS Code 的默认配置。
编码愉快!
Peng Lyu, VS Code 团队成员 @njukidreborn
引用资源:https://code.visualstudio.com/blogs/2018/03/23/text-buffer-reimplementation
文章链接:https://macplay.github.io/en/posts/text-buffer-reimplementation/
发布/更新于:
版权声明:如无特别说明,本站文章均遵循 CC BY-NC-SA 4.0 协议,转载请注明作者及出处。